Tips and Tricks#
This section covers various tips and tricks in a recipe-style fashion.
Benchmarking an Elastic Cloud cluster#
Note
We assume in this recipe, that Rally is already properly configured.
Benchmarking an Elastic Cloud cluster with Rally is similar to benchmarking any other existing cluster. In the following example we will run a benchmark against a cluster reachable via the endpoint https://abcdef123456.europe-west1.gcp.cloud.es.io:9243 by the user elastic with the password changeme:
esrally race --track=pmc --target-hosts=abcdef123456.europe-west1.gcp.cloud.es.io:9243 --pipeline=benchmark-only --client-options="use_ssl:true,verify_certs:true,basic_auth_user:'elastic',basic_auth_password:'changeme'"
Benchmarking an existing cluster#
Warning
If you are just getting started with Rally and don’t understand how it works, do NOT run it against any production or production-like cluster. Besides, benchmarks should be executed in a dedicated environment anyway where no additional traffic skews results.
Note
We assume in this recipe, that Rally is already properly configured.
Consider the following configuration: You have an existing benchmarking cluster, that consists of three Elasticsearch nodes running on 10.5.5.10, 10.5.5.11, 10.5.5.12. You’ve setup the cluster yourself and want to benchmark it with Rally. Rally is installed on 10.5.5.5.
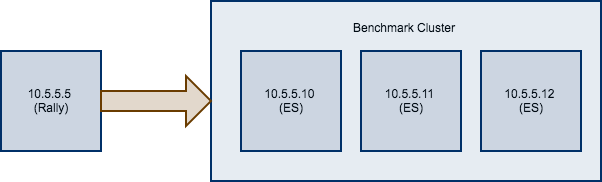
First of all, we need to decide on a track. So, we run esrally list tracks:
Name Description Documents Compressed Size Uncompressed Size Default Challenge All Challenges
---------- ------------------------------------------------- ----------- ----------------- ------------------- ----------------------- ---------------------------
geonames POIs from Geonames 11396505 252.4 MB 3.3 GB append-no-conflicts append-no-conflicts,appe...
geopoint Point coordinates from PlanetOSM 60844404 481.9 MB 2.3 GB append-no-conflicts append-no-conflicts,appe...
http_logs HTTP server log data 247249096 1.2 GB 31.1 GB append-no-conflicts append-no-conflicts,appe...
nested StackOverflow Q&A stored as nested docs 11203029 663.1 MB 3.4 GB nested-search-challenge nested-search-challenge,...
noaa Global daily weather measurements from NOAA 33659481 947.3 MB 9.0 GB append-no-conflicts append-no-conflicts,appe...
nyc_taxis Taxi rides in New York in 2015 165346692 4.5 GB 74.3 GB append-no-conflicts append-no-conflicts,appe...
percolator Percolator benchmark based on AOL queries 2000000 102.7 kB 104.9 MB append-no-conflicts append-no-conflicts,appe...
pmc Full text benchmark with academic papers from PMC 574199 5.5 GB 21.7 GB append-no-conflicts append-no-conflicts,appe...
We’re interested in a full text benchmark, so we’ll choose to run pmc. If you have your own data that you want to use for benchmarks create your own track instead; the metrics you’ll gather will be more representative and useful than some default track.
Next, we need to know which machines to target which is easy as we can see that from the diagram above.
Finally we need to check which pipeline to use. For this case, the benchmark-only pipeline is suitable as we don’t want Rally to provision the cluster for us.
Now we can invoke Rally:
esrally race --track=pmc --target-hosts=10.5.5.10:9200,10.5.5.11:9200,10.5.5.12:9200 --pipeline=benchmark-only
If you have X-Pack Security enabled, then you’ll also need to specify another parameter to use https and to pass credentials:
esrally race --track=pmc --target-hosts=10.5.5.10:9243,10.5.5.11:9243,10.5.5.12:9243 --pipeline=benchmark-only --client-options="use_ssl:true,verify_certs:true,basic_auth_user:'elastic',basic_auth_password:'changeme'"
Benchmarking a remote cluster#
Contrary to the previous recipe, you want Rally to provision all cluster nodes.
We will use the following configuration for the example:
You will start Rally on
10.5.5.5. We will call this machine the “benchmark coordinator”.Your Elasticsearch cluster will consist of two nodes which run on
10.5.5.10and10.5.5.11. We will call these machines the “benchmark candidate”s.
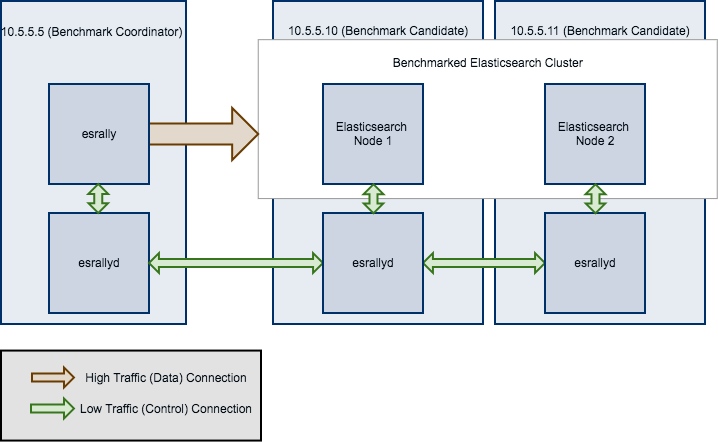
Note
All esrallyd nodes form a cluster that communicates via the “benchmark coordinator”. For aesthetic reasons we do not show a direct connection between the “benchmark coordinator” and all nodes.
To run a benchmark for this scenario follow these steps:
Install and configure Rally on all machines. Be sure that the same version is installed on all of them and fully configured.
Start the Rally daemon on each machine. The Rally daemon allows Rally to communicate with all remote machines. On the benchmark coordinator run
esrallyd start --node-ip=10.5.5.5 --coordinator-ip=10.5.5.5and on the benchmark candidate machines runesrallyd start --node-ip=10.5.5.10 --coordinator-ip=10.5.5.5andesrallyd start --node-ip=10.5.5.11 --coordinator-ip=10.5.5.5respectively. The--node-ipparameter tells Rally the IP of the machine on which it is running. As some machines have more than one network interface, Rally will not attempt to auto-detect the machine IP. The--coordinator-ipparameter tells Rally the IP of the benchmark coordinator node.Start the benchmark by invoking Rally as usual on the benchmark coordinator, for example:
esrally race --track=pmc --distribution-version=7.0.0 --target-hosts=10.5.5.10:39200,10.5.5.11:39200. Rally will derive from the--target-hostsparameter that it should provision the nodes10.5.5.10and10.5.5.11.After the benchmark has finished you can stop the Rally daemon again. On the benchmark coordinator and on the benchmark candidates run
esrallyd stop.
Note
Logs are managed per machine, so all relevant log files and also telemetry output is stored on the benchmark candidates but not on the benchmark coordinator.
Now you might ask yourself what the differences to benchmarks of existing clusters are. In general you should aim to give Rally as much control as possible as benchmark are easier reproducible and you get more metrics. The following table provides some guidance on when to choose which option:
Your requirement |
Recommendation |
|---|---|
You want to use Rally’s telemetry devices |
Use Rally daemon, as it can provision the remote node for you |
You want to benchmark a source build of Elasticsearch |
Use Rally daemon, as it can build Elasticsearch for you |
You want to tweak the cluster configuration yourself |
Use Rally daemon with a custom configuration or set up the cluster by yourself and use |
You need to run a benchmark with plugins |
Use Rally daemon if the plugins are supported or set up the cluster by yourself and use |
You need to run a benchmark against multiple nodes |
Use Rally daemon if all nodes can be configured identically. For more complex cases, set up the cluster by yourself and use |
Rally daemon will be able to cover most of the cases described above in the future so there should be almost no case where you need to use the benchmark-only pipeline.
Distributing the load test driver#
By default, Rally will generate load on the same machine where you start a benchmark. However, when you are benchmarking larger clusters, a single load test driver machine may not be able to generate sufficient load. In these cases, you should use multiple load driver machines. We will use the following configuration for the example:
You will start Rally on
10.5.5.5. We will call this machine the “benchmark coordinator”.You will start two load drivers on
10.5.5.6and10.5.5.7. Note that one load driver will simulate multiple clients. Rally will simply assign clients to load driver machines in a round-robin fashion.Your Elasticsearch cluster will consist of three nodes which run on
10.5.5.11,10.5.5.12and10.5.5.13. We will call these machines the “benchmark candidate”. For simplicity, we will assume an externally provisioned cluster but you can also use Rally to setup the cluster for you (see above).
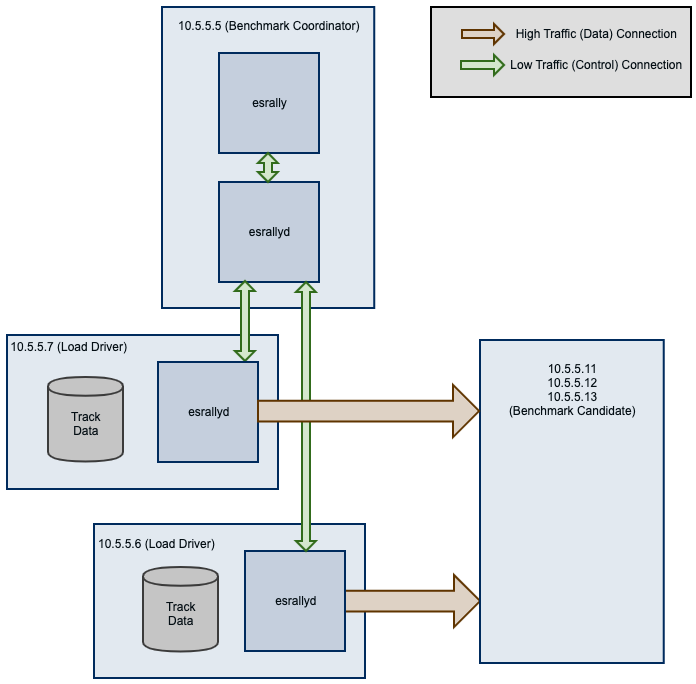
Install and configure Rally on all machines. Be sure that the same version is installed on all of them and fully configured.
Start the Rally daemon on each machine. The Rally daemon allows Rally to communicate with all remote machines. On the benchmark coordinator run
esrallyd start --node-ip=10.5.5.5 --coordinator-ip=10.5.5.5and on the load driver machines runesrallyd start --node-ip=10.5.5.6 --coordinator-ip=10.5.5.5andesrallyd start --node-ip=10.5.5.7 --coordinator-ip=10.5.5.5respectively. The--node-ipparameter tells Rally the IP of the machine on which it is running. As some machines have more than one network interface, Rally will not attempt to auto-detect the machine IP. The--coordinator-ipparameter tells Rally the IP of the benchmark coordinator node.Start the benchmark by invoking Rally on the benchmark coordinator, for example:
esrally race --track=pmc --pipeline=benchmark-only --load-driver-hosts=10.5.5.6,10.5.5.7 --target-hosts=10.5.5.11:9200,10.5.5.12:9200,10.5.5.13:9200.After the benchmark has finished you can stop the Rally daemon again. On the benchmark coordinator and on the load driver machines run
esrallyd stop.
Note
Rally neither distributes code (i.e. custom runners or parameter sources) nor data automatically. You should place all tracks and their data on all machines in the same directory before starting the benchmark. Alternatively, you can store your track in a custom track repository.
Note
As indicated in the diagram, track data will be downloaded by each load driver machine separately. If you want to avoid that, you can run a benchmark once without distributing the load test driver (i.e. do not specify --load-driver-hosts) and then copy the contents of ~/.rally/benchmarks/data to all load driver machines.
Changing the default track repository#
Rally supports multiple track repositories. This allows you for example to have a separate company-internal repository for your own tracks that is separate from Rally’s default track repository. However, you always need to define --track-repository=my-custom-repository which can be cumbersome. If you want to avoid that and want Rally to use your own track repository by default you can just replace the default track repository definition in ~./rally/rally.ini. Consider this example:
...
[tracks]
default.url = git@github.com:elastic/rally-tracks.git
teamtrackrepo.url = git@example.org/myteam/my-tracks.git
If teamtrackrepo should be the default track repository, just define it as default.url. E.g.:
...
[tracks]
default.url = git@example.org/myteam/my-tracks.git
old-rally-default.url=git@github.com:elastic/rally-tracks.git
Also don’t forget to rename the folder of your local working copy as Rally will search for a track repository with the name default:
cd ~/.rally/benchmarks/tracks/
mv default old-rally-default
mv teamtrackrepo default
From now on, Rally will treat your repository as default and you need to run Rally with --track-repository=old-rally-default if you want to use the out-of-the-box Rally tracks.
Testing Rally against CCR clusters using a remote metric store#
Testing Rally features (such as the ccr-stats telemetry device) requiring Elasticsearch clusters configured for cross-cluster replication can be a time consuming process. Use recipes/ccr in Rally’s repository to test a simple but complete example.
Running the start.sh script requires Docker locally installed and performs the following actions:
Starts a single node (512MB heap) Elasticsearch cluster locally, to serve as a metrics store. It also starts Kibana attached to the Elasticsearch metric store cluster.
Creates a new configuration file for Rally under
~/.rally/rally-metricstore.inireferencing Elasticsearch from step 1.Starts two additional local Elasticsearch clusters with 1 node each, (version
7.3.2by default) calledleaderandfollowerlistening at ports 32901 and 32902 respectively. Each node uses 1GB heap.Accepts the trial license.
Configures
leaderon thefolloweras a remote cluster.Sets an auto-follow pattern on the follower for every index on the leader to be replicated as
<leader-index-name>-copy.Runs the geonames track, append-no-conflicts-index-only challenge challenge, ingesting only 20% of the corpus using 3 primary shards. It also enables the
ccr-statstelemetry device with a sample rate interval of1s.
Rally will push metrics to the metric store configured in 1. and they can be visualized by accessing Kibana at http://locahost:5601.
To tear down everything issue ./stop.sh.
It is possible to specify a different version of Elasticsearch for step 3. by setting export ES_VERSION=<the_desired_version>.
Identifying when errors have been encountered#
Custom track development can be error prone especially if you are testing a new query. A number of reasons can lead to queries returning errors.
Consider a simple example Rally operation:
{
"name": "geo_distance",
"operation-type": "search",
"index": "logs-*",
"body": {
"query": {
"geo_distance": {
"distance": "12km",
"source.geo.location": "40,-70"
}
}
}
}
This query requires the field source.geo.location to be mapped as a geo_point type. If incorrectly mapped, Elasticsearch will respond with an error.
Rally will not exit on errors (unless fatal e.g. ECONNREFUSED) by default, instead reporting errors in the summary report via the Error Rate statistic. This can potentially leading to misleading results. This behavior is by design and consistent with other load testing tools such as JMeter i.e. In most cases it is desirable that a large long running benchmark should not fail because of a single error response.
This behavior can also be changed, by invoking Rally with the –on-error switch e.g.:
esrally race --track=geonames --on-error=abort
Checking Queries and Responses#
As described above, errors can lead to misleading benchmarking results. Some issues, however, are more subtle and the result of queries not behaving and matching as intended.
Consider the following simple Rally operation:
{
"name": "geo_distance",
"operation-type": "search",
"detailed-results": true,
"index": "logs-*",
"body": {
"query": {
"term": {
"http.request.method": {
"value": "GET"
}
}
}
}
}
For this term query to match the field http.request.method needs to be type keyword. Should this field be dynamically mapped, its default type will be text causing the value GET to be analyzed, and indexed as get. The above query will in turn return 0 hits. The field should either be correctly mapped or the query modified to match on http.request.method.keyword.
Issues such as this can lead to misleading benchmarking results. Prior to running any benchmarks for analysis, we therefore recommended users ascertain whether queries are behaving as intended. Rally provides several tools to assist with this.
Firstly, users can set the log level for the Elasticsearch client to DEBUG i.e.:
"loggers": {
"elasticsearch": {
"handlers": ["rally_log_handler"],
"level": "DEBUG",
"propagate": false
},
"rally.profile": {
"handlers": ["rally_profile_handler"],
"level": "INFO",
"propagate": false
}
}
This will in turn ensure logs include the Elasticsearch query and accompanying response e.g.:
2019-12-16 14:56:08,389 -not-actor-/PID:9790 elasticsearch DEBUG > {"sort":[{"geonameid":"asc"}],"query":{"match_all":{}}}
2019-12-16 14:56:08,389 -not-actor-/PID:9790 elasticsearch DEBUG < {"took":1,"timed_out":false,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0},"hits":{"total":{"value":1000,"relation":"eq"},"max_score":null,"hits":[{"_index":"geonames","_type":"_doc","_id":"Lb81D28Bu7VEEZ3mXFGw","_score":null,"_source":{"geonameid": 2986043, "name": "Pic de Font Blanca", "asciiname": "Pic de Font Blanca", "alternatenames": "Pic de Font Blanca,Pic du Port", "feature_class": "T", "feature_code": "PK", "country_code": "AD", "admin1_code": "00", "population": 0, "dem": "2860", "timezone": "Europe/Andorra", "location": [1.53335, 42.64991]},"sort":[2986043]},
Users should discard any performance metrics collected from a benchmark with DEBUG logging. This will likely cause a client-side bottleneck so once the correctness of the queries has been established, disable this setting and re-run any benchmarks.
The number of hits from queries can also be investigated if you have configured a dedicated Elasticsearch metrics store. Specifically, documents within the index pattern rally-metrics-* contain a meta field with a summary of individual responses e.g.:
{
"@timestamp" : 1597681313435,
"relative-time" : 130273.374,
"race-id" : "452ad9d7-9c21-4828-848e-89974af3230e",
"race-timestamp" : "20200817T160412Z",
"environment" : "Personal",
"track" : "geonames",
"challenge" : "append-no-conflicts",
"car" : "defaults",
"name" : "latency",
"value" : 270.77871300025436,
"unit" : "ms",
"sample-type" : "warmup",
"meta" : {
"source_revision" : "757314695644ea9a1dc2fecd26d1a43856725e65",
"distribution_version" : "7.8.0",
"distribution_flavor" : "oss",
"pages" : 25,
"hits" : 11396503,
"hits_relation" : "eq",
"timed_out" : false,
"took" : 110,
"success" : true
},
"task" : "scroll",
"operation" : "scroll",
"operation-type" : "Search"
}
Finally, it is also possible to add assertions to an operation:
{
"name": "geo_distance",
"operation-type": "search",
"detailed-results": true,
"index": "logs-*",
"assertions": [
{
"property": "hits",
"condition": ">",
"value": 0
}
],
"body": {
"query": {
"term": {
"http.request.method": {
"value": "GET"
}
}
}
}
}
When a benchmark is executed with --enable-assertions and this query returns no hits, the benchmark is aborted with a message:
[ERROR] Cannot race. Error in load generator [0]
Cannot run task [geo_distance]: Expected [hits] to be > [0] but was [0].