Recipes¶
Benchmarking an existing cluster¶
Warning
If you are just getting started with Rally and don’t understand how it works, please do NOT run it against any production or production-like cluster. Besides, benchmarks should be executed in a dedicated environment anyway where no additional traffic skews results.
Note
We assume in this recipe, that Rally is already properly configured.
Consider the following configuration: You have an existing benchmarking cluster, that consists of three Elasticsearch nodes running on 10.5.5.10, 10.5.5.11, 10.5.5.12. You’ve setup the cluster yourself and want to benchmark it with Rally. Rally is installed on 10.5.5.5.
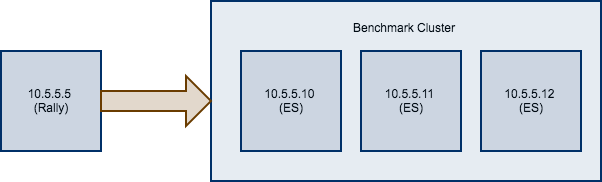
First of all, we need to decide on a track. So, we run esrally list tracks:
Name Description Challenges
---------- -------------------------------------------------------------------- -----------------------------------------------------------------------------------------------------------------------------------------------
geonames Standard benchmark in Rally (8.6M POIs from Geonames) append-no-conflicts,append-no-conflicts-index-only,append-no-conflicts-index-only-1-replica,append-fast-no-conflicts,append-fast-with-conflicts
geopoint 60.8M POIs from PlanetOSM append-no-conflicts,append-no-conflicts-index-only,append-no-conflicts-index-only-1-replica,append-fast-no-conflicts,append-fast-with-conflicts
logging Logging benchmark append-no-conflicts,append-no-conflicts-index-only,append-no-conflicts-index-only-1-replica,append-fast-no-conflicts,append-fast-with-conflicts
nyc_taxis Trip records completed in yellow and green taxis in New York in 2015 append-no-conflicts,append-no-conflicts-index-only,append-no-conflicts-index-only-1-replica
percolator Percolator benchmark based on 2M AOL queries append-no-conflicts
pmc Full text benchmark containing 574.199 papers from PMC append-no-conflicts,append-no-conflicts-index-only,append-no-conflicts-index-only-1-replica,append-fast-no-conflicts,append-fast-with-conflicts
We’re interested in a full text benchmark, so we’ll choose to run pmc. If you have your own data that you want to use for benchmarks, then please create your own track instead; the metrics you’ll gather which be representative and much more useful than some default track.
Next, we need to know which machines to target which is easy as we can see that from the diagram above.
Finally we need to check which pipeline to use. For this case, the benchmark-only pipeline is suitable as we don’t want Rally to provision the cluster for us.
Now we can invoke Rally:
esrally --track=pmc --target-hosts=10.5.5.10:9200,10.5.5.11:9200,10.5.5.12:9200 --pipeline=benchmark-only
If you have X-Pack Security enabled, then you’ll also need to specify another parameter to use https and to pass credentials:
esrally --track=pmc --target-hosts=10.5.5.10:9243,10.5.5.11:9243,10.5.5.12:9243 --pipeline=benchmark-only --client-options="basic_auth_user:'elastic',basic_auth_password:'changeme'"