Track Reference¶
Definition¶
A track is a specification of one or more benchmarking scenarios with a specific document corpus. It defines for example the involved indices, data files and the operations that are invoked. Its most important attributes are:
- One or more indices, each with one or more types
- The queries to issue
- Source URL of the benchmark data
- A list of steps to run, which we’ll call “challenge”, for example indexing data with a specific number of documents per bulk request or running searches for a defined number of iterations.
Track File Format and Storage¶
A track is specified in a JSON file.
Ad-hoc use¶
For ad-hoc use you can store a track definition anywhere on the file system and reference it with --track-path, e.g:
# provide a directory - Rally searches for a track.json file in this directory
# Track name is "app-logs"
esrally --track-path=~/Projects/tracks/app-logs
# provide a file name - Rally uses this file directly
# Track name is "syslog"
esrally --track-path=~/Projects/tracks/syslog.json
Rally will also search for additional files like mappings or data files in the provided directory. If you use advanced features like custom runners or parameter sources we recommend that you create a separate directory per track.
Custom Track Repositories¶
Alternatively, you can store Rally tracks also in a dedicated git repository which we call a “track repository”. Rally provides a default track repository that is hosted on Github. You can also add your own track repositories although this requires a bit of additional work. First of all, track repositories need to be managed by git. The reason is that Rally can benchmark multiple versions of Elasticsearch and we use git branches in the track repository to determine the best match for each track (based on the command line parameter --distribution-version). The versioning scheme is as follows:
- The master branch needs to work with the latest master branch of Elasticsearch.
- All other branches need to match the version scheme of Elasticsearch, i.e.
MAJOR.MINOR.PATCH-SUFFIXwhere all parts exceptMAJORare optional.
Rally implements a fallback logic so you don’t need to define a branch for each patch release of Elasticsearch. For example:
- The branch 6.0.0-alpha1 will be chosen for the version
6.0.0-alpha1of Elasticsearch. - The branch 5 will be chosen for all versions for Elasticsearch with the major version 5, e.g.
5.0.0,5.1.3(provided there is no specific branch).
Rally tries to use the branch with the best match to the benchmarked version of Elasticsearch.
Rally will also search for related files like mappings or custom runners or parameter sources in the track repository. However, Rally will use a separate directory to look for data files (~/.rally/benchmarks/data/$TRACK_NAME/). The reason is simply that we do not want to check multi-GB data files into git.
Creating a new track repository¶
All track repositories are located in ~/.rally/benchmarks/tracks. If you want to add a dedicated track repository, called private follow these steps:
cd ~/.rally/benchmarks/tracks
mkdir private
cd private
git init
# add your track now
git add .
git commit -m "Initial commit"
If you want to share your tracks with others you need to add a remote and push it:
git remote add origin git@git-repos.acme.com:acme/rally-tracks.git
git push -u origin master
If you have added a remote you should also add it in ~/.rally/rally.ini, otherwise you can skip this step. Open the file in your editor of choice and add the following line in the section tracks:
private.url = <<URL_TO_YOUR_ORIGIN>>
If you specify --track-repository=private, Rally will check whether there is a directory ~/.rally/benchmarks/tracks/private. If there is none, it will use the provided URL to clone the repo. However, if the directory already exists, the property gets ignored and Rally will just update the local tracking branches before the benchmark starts.
You can now verify that everything works by listing all tracks in this track repository:
esrally list tracks --track-repository=private
This shows all tracks that are available on the master branch of this repository. Suppose you only created tracks on the branch 2 because you’re interested in the performance of Elasticsearch 2.x, then you can specify also the distribution version:
esrally list tracks --track-repository=private --distribution-version=2.0.0
Rally will follow the same branch fallback logic as described above.
Adding an already existing track repository¶
If you want to add a track repository that already exists, just open ~/.rally/rally.ini in your editor of choice and add the following line in the section tracks:
your_repo_name.url = <<URL_TO_YOUR_ORIGIN>>
After you have added this line, have Rally list the tracks in this repository:
esrally list tracks --track-repository=your_repo_name
When to use what?¶
We recommend the following path:
- Start with a simple json file. The file name can be arbitrary.
- If you need custom runners or parameter sources, create one directory per track. Then you can keep everything that is related to one track in one place. Remember that the track JSON file needs to be named
track.json. - If you want to version your tracks so they can work with multiple versions of Elasticsearch (e.g. you are running benchmarks before an upgrade), use a track repository.
Anatomy of a track¶
A track JSON file consists of the following sections:
- indices
- templates
- corpora
- operations
- schedule
In the indices and templates sections you define the relevant indices and index templates. These sections are optional but recommended if you want to create indices and index templates with the help of Rally.
In the corpora section you define all document corpora (i.e. data files) that Rally should use for this track.
In the operations section you describe which operations are available for this track and how they are parametrized. This section is optional and you can also define any operations directly per challenge. You can use it, if you want to share operation definitions between challenges.
In the schedule section you describe the workload for the benchmark, for example index with two clients at maximum throughput while searching with another two clients with ten operations per second. The schedule either uses the operations defined in the operations block or defines the operations to execute inline.
Track elements¶
The track elements that are described here are defined in Rally’s JSON schema for tracks. Rally uses this track schema to validate your tracks when it is loading them.
Each track defines the following info attributes:
version(optional): An integer describing the track specification version in use. Rally uses it to detect incompatible future track specification versions and raise an error. See the table below for a reference of valid versions.description(optional): A human-readable description of the track. Although it is optional, we recommend providing it.
| Track Specification Version | Rally version |
|---|---|
| 1 | >=0.7.3, <0.10.0 |
| 2 | >=0.9.0 |
The version property has been introduced with Rally 0.7.3. Rally versions before 0.7.3 do not recognize this property and thus cannot detect incompatible track specification versions.
Example:
{
"version": 2,
"description": "POIs from Geonames"
}
meta¶
For each track, an optional structure, called meta can be defined. You are free which properties this element should contain.
This element can also be defined on the following elements:
challengeoperationtask
If the meta structure contains the same key on different elements, more specific ones will override the same key of more generic elements. The order from generic to most specific is:
- track
- challenge
- operation
- task
E.g. a key defined on a task, will override the same key defined on a challenge. All properties defined within the merged meta structure, will get copied into each metrics record.
indices¶
The indices section contains a list of all indices that are used by this track.
Each index in this list consists of the following properties:
name(mandatory): The name of the index.body(optional): File name of the corresponding index definition that will be used as body in the create index API call.types(optional): A list of type names in this index. Types have been removed in Elasticsearch 7.0.0 so you must not specify this property if you want to benchmark Elasticsearch 7.0.0 or later.
Example:
"indices": [
{
"name": "geonames",
"body": "geonames-index.json",
"types": ["docs"]
}
]
templates¶
The templates section contains a list of all index templates that Rally should create.
name(mandatory): Index template nameindex-pattern(mandatory): Index pattern that matches the index template. This must match the definition in the index template file.delete-matching-indices(optional, defaults totrue): Delete all indices that match the provided index pattern before start of the benchmark.template(mandatory): Index template file name
Example:
"templates": [
{
"name": "my-default-index-template",
"index-pattern": "my-index-*",
"delete-matching-indices": true,
"template": "default-template.json"
}
]
corpora¶
The corpora section contains all document corpora that are used by this track. Note that you can reuse document corpora across tracks; just copy & paste the respective corpora definitions. It consists of the following properties:
name(mandatory): Name of this document corpus. As this name is also used by Rally in directory names, it is recommended to only use lower-case names without whitespaces for maximum compatibility across file systems.documents(mandatory): A list of documents files.
Each entry in the documents list consists of the following properties:
base-url(optional): A http(s) or S3 URL that points to the root path where Rally can obtain the corresponding source file. Rally can also download data from private S3 buckets if access is properly configured.source-format(optional, default:bulk): Defines in which format Rally should interpret the data file specified bysource-file. Currently, onlybulkis supported.source-file(mandatory): File name of the corresponding documents. For local use, this file can be a.jsonfile. If you provide abase-urlwe recommend that you provide a compressed file here. The following extensions are supported:.zip,.bz2,.gz,.tar,.tar.gz,.tgzor.tar.bz2. It must contain exactly one JSON file with the same name. The preferred file extension for our official tracks is.bz2.includes-action-and-meta-data(optional, defaults tofalse): Defines whether the documents file contains already an action and meta-data line (true) or only documents (false).document-count(mandatory): Number of documents in the source file. This number is used by Rally to determine which client indexes which part of the document corpus (each of the N clients gets one N-th of the document corpus). If you are using parent-child, specify the number of parent documents.compressed-bytes(optional but recommended): The size in bytes of the compressed source file. This number is used to show users how much data will be downloaded by Rally and also to check whether the download is complete.uncompressed-bytes(optional but recommended): The size in bytes of the source file after decompression. This number is used by Rally to show users how much disk space the decompressed file will need and to check that the whole file could be decompressed successfully.target-index: Defines the name of the index which should be targeted for bulk operations. Rally will automatically derive this value if you have defined exactly one index in theindicessection. Ignored ifincludes-action-and-meta-dataistrue.target-type(optional): Defines the name of the document type which should be targeted for bulk operations. Rally will automatically derive this value if you have defined exactly one index in theindicessection and this index has exactly one type. Ignored ifincludes-action-and-meta-dataistrue. Types have been removed in Elasticsearch 7.0.0 so you must not specify this property if you want to benchmark Elasticsearch 7.0.0 or later.
To avoid repetition, you can specify default values on document corpus level for the following properties:
base-urlsource-formatincludes-action-and-meta-datatarget-indextarget-type
Examples
Here we define a single document corpus with one set of documents:
"corpora": [
{
"name": "geonames",
"documents": [
{
"base-url": "http://benchmarks.elasticsearch.org.s3.amazonaws.com/corpora/geonames",
"source-file": "documents.json.bz2",
"document-count": 11396505,
"compressed-bytes": 264698741,
"uncompressed-bytes": 3547614383,
"target-index": "geonames",
"target-type": "docs"
}
]
}
]
We can also define default values on document corpus level but override some of them (base-url for the last entry):
"corpora": [
{
"name": "http_logs",
"base-url": "http://benchmarks.elasticsearch.org.s3.amazonaws.com/corpora/http_logs",
"target-type": "docs",
"documents": [
{
"source-file": "documents-181998.json.bz2",
"document-count": 2708746,
"target-index": "logs-181998"
},
{
"source-file": "documents-191998.json.bz2",
"document-count": 9697882,
"target-index": "logs-191998"
},
{
"base-url": "http://example.org/corpora/http_logs",
"source-file": "documents-201998.json.bz2",
"document-count": 13053463,
"target-index": "logs-201998"
}
]
}
]
operations¶
The operations section contains a list of all operations that are available later when specifying a schedule. Operations define the static properties of a request against Elasticsearch whereas the schedule element defines the dynamic properties (such as the target throughput).
Each operation consists of the following properties:
name(mandatory): The name of this operation. You can choose this name freely. It is only needed to reference the operation when defining schedules.operation-type(mandatory): Type of this operation. See below for the operation types that are supported out of the box in Rally. You can also add arbitrary operations by defining custom runners.include-in-reporting(optional, defaults totruefor normal operations and tofalsefor administrative operations): Whether or not this operation should be included in the command line report. For example you might want Rally to create an index for you but you are not interested in detailed metrics about it. Note that Rally will still record all metrics in the metrics store.
Depending on the operation type a couple of further parameters can be specified.
bulk¶
With the operation type bulk you can execute bulk requests. It supports the following properties:
bulk-size(mandatory): Defines the bulk size in number of documents.ingest-percentage(optional, defaults to 100): A number between (0, 100] that defines how much of the document corpus will be bulk-indexed.corpora(optional): A list of document corpus names that should be targeted by this bulk-index operation. Only needed if thecorporasection contains more than one document corpus and you don’t want to index all of them with this operation.indices(optional): A list of index names that defines which indices should be used by this bulk-index operation. Rally will then only select the documents files that have a matchingtarget-indexspecified.batch-size(optional): Defines how many documents Rally will read at once. This is an expert setting and only meant to avoid accidental bottlenecks for very small bulk sizes (e.g. if you want to benchmark with a bulk-size of 1, you should setbatch-sizehigher).pipeline(optional): Defines the name of an (existing) ingest pipeline that should be used (only supported from Elasticsearch 5.0).conflicts(optional): Type of index conflicts to simulate. If not specified, no conflicts will be simulated (also read below on how to use external index ids with no conflicts). Valid values are: ‘sequential’ (A document id is replaced with a document id with a sequentially increasing id), ‘random’ (A document id is replaced with a document id with a random other id).conflict-probability(optional, defaults to 25 percent): A number between [0, 100] that defines how many of the documents will get replaced. Combiningconflicts=sequentialandconflict-probability=0makes Rally generate index ids by itself, instead of relying on Elasticsearch’s automatic id generation.on-conflict(optional, defaults toindex): Determines whether Rally should use the actionindexorupdateon id conflicts.recency(optional, defaults to 0): A number between [0,1] indicating whether to bias conflicting ids towards more recent ids (recencytowards 1) or whether to consider all ids for id conflicts (recencytowards 0). See the diagram below for details.detailed-results(optional, defaults tofalse): Records more detailed meta-data for bulk requests. As it analyzes the corresponding bulk response in more detail, this might incur additional overhead which can skew measurement results.
The image below shows how Rally behaves with a recency set to 0.5. Internally, Rally uses the blue function for its calculations but to understand the behavior we will focus on red function (which is just the inverse). Suppose we have already generated ids from 1 to 100 and we are about to simulate an id conflict. Rally will randomly choose a value on the y-axis, e.g. 0.8 which is mapped to 0.1 on the x-axis. This means that in 80% of all cases, Rally will choose an id within the most recent 10%, i.e. between 90 and 100. With 20% probability the id will be between 1 and 89. The closer recency gets to zero, the “flatter” the red curve gets and the more likely Rally will choose less recent ids.
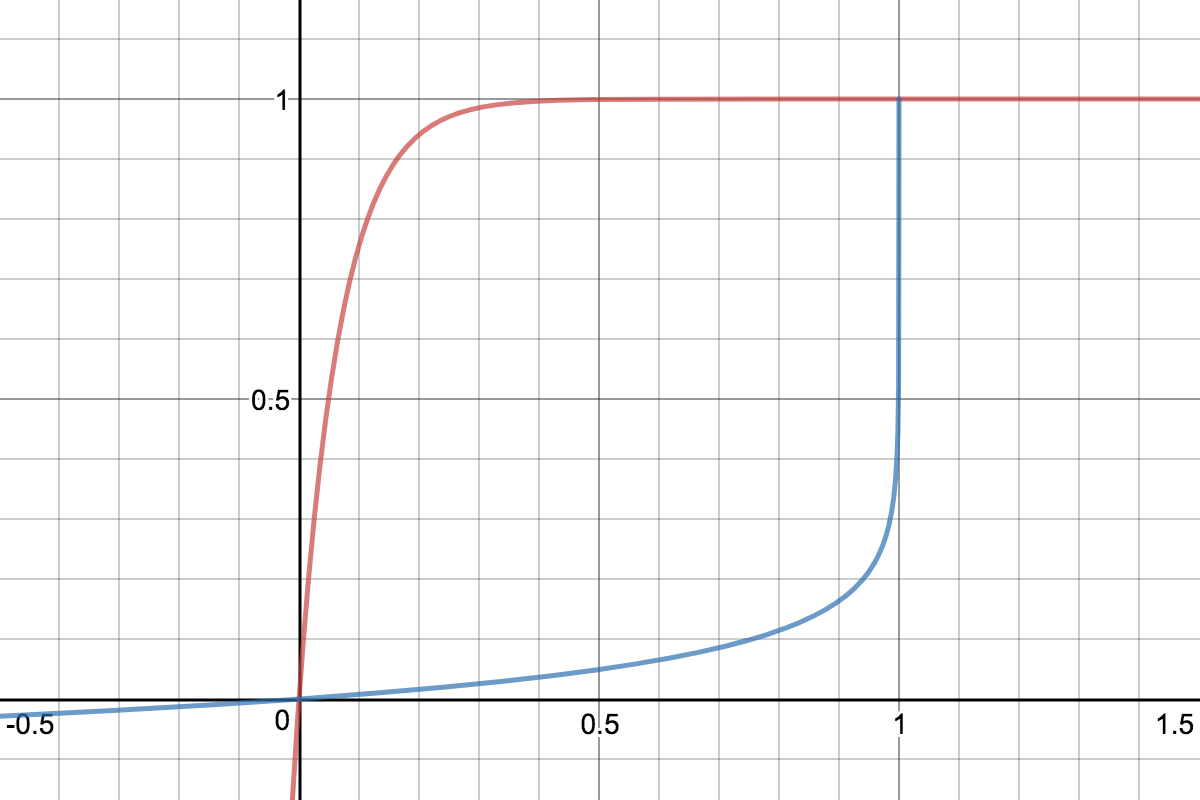
You can also explore the recency calculation interactively.
Example:
{
"name": "index-append",
"operation-type": "bulk",
"bulk-size": 5000
}
Throughput will be reported as number of indexed documents per second.
force-merge¶
With the operation type force-merge you can call the force merge API. On older versions of Elasticsearch (prior to 2.1), Rally will use the optimize API instead. It supports the following parameters:
index(optional, defaults to the indices defined in theindicessection or_allif no indices are defined there): The name of the index that should be force-merged.max-num-segments(optional) The number of segments the index should be merged into. Defaults to simply checking if a merge needs to execute, and if so, executes it.
This is an administrative operation. Metrics are not reported by default. If reporting is forced by setting include-in-reporting to true, then throughput is reported as the number of completed force-merge operations per second.
index-stats¶
With the operation type index-stats you can call the indices stats API. It does not support any parameters.
Throughput will be reported as number of completed index-stats operations per second.
node-stats¶
With the operation type nodes-stats you can execute nodes stats API. It does not support any parameters.
Throughput will be reported as number of completed node-stats operations per second.
search¶
With the operation type search you can execute request body searches. It supports the following properties:
index(optional): An index pattern that defines which indices should be targeted by this query. Only needed if theindexsection contains more than one index. Otherwise, Rally will automatically derive the index to use. If you have defined multiple indices and want to query all of them, just specify"index": "_all".type(optional): Defines the type within the specified index for this query. By default, notypewill be used and the query will be performed across all types in the provided index. Also, types have been removed in Elasticsearch 7.0.0 so you must not specify this property if you want to benchmark Elasticsearch 7.0.0 or later.cache(optional): Whether to use the query request cache. By default, Rally will define no value thus the default depends on the benchmark candidate settings and Elasticsearch version.request-params(optional): A structure containing arbitrary request parameters. The supported parameters names are documented in the Search URI Request docs.Note
- Parameters that are implicitly set by Rally (e.g. body or request_cache) are not supported (i.e. you should not try to set them and if so expect unspecified behavior).
- Rally will not attempt to serialize the parameters and pass them as is. Always use “true” / “false” strings for boolean parameters (see example below).
body(mandatory): The query body.pages(optional): Number of pages to retrieve. If this parameter is present, a scroll query will be executed. If you want to retrieve all result pages, use the value “all”.results-per-page(optional): Number of documents to retrieve per page for scroll queries.
Example:
{
"name": "default",
"operation-type": "search",
"body": {
"query": {
"match_all": {}
}
},
"request-params": {
"_source_include": "some_field",
"analyze_wildcard": "false"
}
}
For scroll queries, throughput will be reported as number of retrieved scroll pages per second. The unit is ops/s, where one op(eration) is one page that has been retrieved. The rationale is that each HTTP request corresponds to one operation and we need to issue one HTTP request per result page. Note that if you use a dedicated Elasticsearch metrics store, you can also use other request-level meta-data such as the number of hits for your own analyses.
For other queries, throughput will be reported as number of search requests per second, also measured as ops/s.
put-pipeline¶
With the operation-type put-pipeline you can execute the put pipeline API. Note that this API is only available from Elasticsearch 5.0 onwards. It supports the following properties:
- id (mandatory): Pipeline id
- body (mandatory): Pipeline definition
In this example we setup a pipeline that adds location information to a ingested document as well as a pipeline failure block to change the index in which the document was supposed to be written. Note that we need to use the raw and endraw blocks to ensure that Rally does not attempt to resolve the Mustache template. See template language for more information.
Example:
{
"name": "define-ip-geocoder",
"operation-type": "put-pipeline",
"id": "ip-geocoder",
"body": {
"description": "Extracts location information from the client IP.",
"processors": [
{
"geoip": {
"field": "clientip",
"properties": [
"city_name",
"country_iso_code",
"country_name",
"location"
]
}
}
],
"on_failure": [
{
"set": {
"field": "_index",
{% raw %}
"value": "failed-{{ _index }}"
{% endraw %}
}
}
]
}
}
Please see the pipeline documentation for details on handling failures in pipelines.
This example requires that the ingest-geoip Elasticsearch plugin is installed.
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
put-settings¶
With the operation-type put-settings you can execute the cluster update settings API. It supports the following properties:
- body (mandatory): The cluster settings to apply.
Example:
{
"name": "increase-watermarks",
"operation-type": "put-settings",
"body": {
"transient" : {
"cluster.routing.allocation.disk.watermark.low" : "95%",
"cluster.routing.allocation.disk.watermark.high" : "97%",
"cluster.routing.allocation.disk.watermark.flood_stage" : "99%"
}
}
}
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
cluster-health¶
With the operation cluster-health you can execute the cluster health API. It supports the following properties:
request-params(optional): A structure containing any request parameters that are allowed by the cluster health API. Rally will not attempt to serialize the parameters and pass them as is. Always use “true” / “false” strings for boolean parameters (see example below).index(optional): The name of the index that should be used to check.
The cluster-health operation will check whether the expected cluster health and will report a failure if this is not the case. Use --on-error on the command line to control Rally’s behavior in case of such failures.
Example:
{
"name": "check-cluster-green",
"operation-type": "cluster-health",
"index": "logs-*",
"request-params": {
"wait_for_status": "green",
"wait_for_no_relocating_shards": "true"
}
}
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
refresh¶
With the operation refresh you can execute the refresh API. It supports the following properties:
index(optional, defaults to_all): The name of the index that should be refreshed.
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
create-index¶
With the operation create-index you can execute the create index API. It supports two modes: it creates either all indices that are specified in the track’s indices section or it creates one specific index defined by this operation.
If you want it to create all indices that have been declared in the indices section you can specify the following properties:
settings(optional): Allows to specify additional index settings that will be merged with the index settings specified in the body of the index in theindicessection.request-params(optional): A structure containing any request parameters that are allowed by the create index API. Rally will not attempt to serialize the parameters and pass them as is. Always use “true” / “false” strings for boolean parameters (see example below).
If you want it to create one specific index instead, you can specify the following properties:
index(mandatory): One or more names of the indices that should be created. If only one index should be created, you can use a string otherwise this needs to be a list of strings.body(optional): The body for the create index API call.request-params(optional): A structure containing any request parameters that are allowed by the create index API. Rally will not attempt to serialize the parameters and pass them as is. Always use “true” / “false” strings for boolean parameters (see example below).
Examples
The following snippet will create all indices that have been defined in the indices section. It will reuse all settings defined but override the number of shards:
{
"name": "create-all-indices",
"operation-type": "create-index",
"settings": {
"index.number_of_shards": 1
},
"request-params": {
"wait_for_active_shards": "true"
}
}
With the following snippet we will create a new index that is not defined in the indices section. Note that we specify the index settings directly in the body:
{
"name": "create-an-index",
"operation-type": "create-index",
"index": "people",
"body": {
"settings": {
"index.number_of_shards": 0
},
"mappings": {
"docs": {
"properties": {
"name": {
"type": "text"
}
}
}
}
}
}
Note
Types have been removed in Elasticsearch 7.0.0. If you want to benchmark Elasticsearch 7.0.0 or later you need to remove the mapping type above.
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
delete-index¶
With the operation delete-index you can execute the delete index API. It supports two modes: it deletes either all indices that are specified in the track’s indices section or it deletes one specific index (pattern) defined by this operation.
If you want it to delete all indices that have been declared in the indices section, you can specify the following properties:
only-if-exists(optional, defaults totrue): Defines whether an index should only be deleted if it exists.request-params(optional): A structure containing any request parameters that are allowed by the delete index API. Rally will not attempt to serialize the parameters and pass them as is. Always use “true” / “false” strings for boolean parameters (see example below).
If you want it to delete one specific index (pattern) instead, you can specify the following properties:
index(mandatory): One or more names of the indices that should be deleted. If only one index should be deleted, you can use a string otherwise this needs to be a list of strings.only-if-exists(optional, defaults totrue): Defines whether an index should only be deleted if it exists.request-params(optional): A structure containing any request parameters that are allowed by the delete index API. Rally will not attempt to serialize the parameters and pass them as is. Always use “true” / “false” strings for boolean parameters (see example below).
Examples
With the following snippet we will delete all indices that are declared in the indices section but only if they existed previously (implicit default):
{
"name": "delete-all-indices",
"operation-type": "delete-index"
}
With the following snippet we will delete all logs-* indices:
{
"name": "delete-logs",
"operation-type": "delete-index",
"index": "logs-*",
"only-if-exists": false,
"request-params": {
"expand_wildcards": "all",
"allow_no_indices": "true",
"ignore_unavailable": "true"
}
}
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
create-index-template¶
With the operation create-index-template you can execute the create index template API. It supports two modes: it creates either all index templates that are specified in the track’s templates section or it creates one specific index template defined by this operation.
If you want it to create index templates that have been declared in the templates section you can specify the following properties:
template(optional): If you specify a template name, only the template with this name will be created.settings(optional): Allows to specify additional settings that will be merged with the settings specified in the body of the index template in thetemplatessection.request-params(optional): A structure containing any request parameters that are allowed by the create index template API. Rally will not attempt to serialize the parameters and pass them as is. Always use “true” / “false” strings for boolean parameters (see example below).
If you want it to create one specific index instead, you can specify the following properties:
template(mandatory): The name of the index template that should be created.body(mandatory): The body for the create index template API call.request-params(optional): A structure containing any request parameters that are allowed by the create index template API. Rally will not attempt to serialize the parameters and pass them as is. Always use “true” / “false” strings for boolean parameters (see example below).
Examples
The following snippet will create all index templates that have been defined in the templates section:
{
"name": "create-all-templates",
"operation-type": "create-index-template",
"request-params": {
"create": "true"
}
}
With the following snippet we will create a new index template that is not defined in the templates section. Note that we specify the index template settings directly in the body:
{
"name": "create-a-template",
"operation-type": "create-index-template",
"template": "defaults",
"body": {
"index_patterns": ["*"],
"settings": {
"number_of_shards": 3
},
"mappings": {
"docs": {
"_source": {
"enabled": false
}
}
}
}
}
Note
Types have been removed in Elasticsearch 7.0.0. If you want to benchmark Elasticsearch 7.0.0 or later you need to remove the mapping type above.
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
delete-index-template¶
With the operation delete-index-template you can execute the delete index template API. It supports two modes: it deletes either all index templates that are specified in the track’s templates section or it deletes one specific index template defined by this operation.
If you want it to delete all index templates that have been declared in the templates section, you can specify the following properties:
only-if-exists(optional, defaults totrue): Defines whether an index template should only be deleted if it exists.request-params(optional): A structure containing any request parameters that are allowed by the delete index template API. Rally will not attempt to serialize the parameters and pass them as is. Always use “true” / “false” strings for boolean parameters.
If you want it to delete one specific index template instead, you can specify the following properties:
template(mandatory): The name of the index that should be deleted.only-if-exists(optional, defaults totrue): Defines whether the index template should only be deleted if it exists.delete-matching-indices(optional, defaults tofalse): Whether to delete indices that match the index template’s index pattern.index-pattern(mandatory iffdelete-matching-indicesistrue): Specifies the index pattern to delete.request-params(optional): A structure containing any request parameters that are allowed by the delete index template API. Rally will not attempt to serialize the parameters and pass them as is. Always use “true” / “false” strings for boolean parameters.
Examples
With the following snippet we will delete all index templates that are declared in the templates section but only if they existed previously (implicit default):
{
"name": "delete-all-index-templates",
"operation-type": "delete-index-template"
}
With the following snippet we will delete the default` index template:
{
"name": "delete-default-template",
"operation-type": "delete-index-template",
"template": "default",
"only-if-exists": false,
"delete-matching-indices": true,
"index-pattern": "*"
}
Note
If delete-matching-indices is set to true, indices with the provided index-pattern are deleted regardless whether the index template has previously existed.
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
shrink-index¶
With the operation shrink-index you can execute the shrink index API. Note that this does not correspond directly to the shrink index API call in Elasticsearch but it is a high-level operation that executes all the necessary low-level operations under the hood to shrink an index. It supports the following parameters:
source-index(mandatory): The name of the index that should be shrinked.target-index(mandatory): The name of the index that contains the shrinked shards.target-body(mandatory): The body containing settings and aliases fortarget-index.shrink-node(optional, defaults to a random data node): As a first step, the source index needs to be fully relocated to a single node. Rally will automatically choose a random data node in the cluster but you can choose one explicitly if needed.
Example:
{
"operation-type": "shrink-index",
"shrink-node": "rally-node-0",
"source-index": "src",
"target-index": "target",
"target-body": {
"settings": {
"index.number_of_replicas": 1,
"index.number_of_shards": 1,
"index.codec": "best_compression"
}
}
}
This will shrink the index src to target. The target index will consist of one shard and have one replica. With shrink-node we also explicitly specify the name of the node where we want the source index to be relocated to.
delete-ml-datafeed¶
With the operation delete-ml-datafeed you can execute the delete datafeeds API. The delete-ml-datafeed operation supports the following parameters:
datafeed-id(mandatory): The name of the machine learning datafeed to delete.force(optional, defaults tofalse): Whether to force deletion of a datafeed that has already been started.
This runner will intentionally ignore 404s from Elasticsearch so it is safe to execute this runner regardless whether a corresponding machine learning datafeed exists.
This operation works only if machine-learning is properly installed and enabled. This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
create-ml-datafeed¶
With the operation create-ml-datafeed you can execute the create datafeeds API. The create-ml-datafeed operation supports the following parameters:
datafeed-id(mandatory): The name of the machine learning datafeed to create.body(mandatory): Request body containing the definition of the datafeed. Please see the create datafeed API documentation for more details.
This operation works only if machine-learning is properly installed and enabled. This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
start-ml-datafeed¶
With the operation start-ml-datafeed you can execute the start datafeeds API. The start-ml-datafeed operation supports the following parameters which are documented in the start datafeed API documentation:
datafeed-id(mandatory): The name of the machine learning datafeed to start.body(optional, defaults to empty): Request body with start parameters.start(optional, defaults to empty): Start timestamp of the datafeed.end(optional, defaults to empty): End timestamp of the datafeed.timeout(optional, defaults to empty): Amount of time to wait until a datafeed starts.
This operation works only if machine-learning is properly installed and enabled. This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
stop-ml-datafeed¶
With the operation stop-ml-datafeed you can execute the stop datafeed API. The stop-ml-datafeed operation supports the following parameters:
datafeed-id(mandatory): The name of the machine learning datafeed to start.force(optional, defaults tofalse): Whether to forcefully stop an already started datafeed.timeout(optional, defaults to empty): Amount of time to wait until a datafeed stops.
This operation works only if machine-learning is properly installed and enabled. This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
delete-ml-job¶
With the operation delete-ml-job you can execute the delete jobs API. The delete-ml-job operation supports the following parameters:
job-id(mandatory): The name of the machine learning job to delete.force(optional, defaults tofalse): Whether to force deletion of a job that has already been opened.
This runner will intentionally ignore 404s from Elasticsearch so it is safe to execute this runner regardless whether a corresponding machine learning job exists.
This operation works only if machine-learning is properly installed and enabled. This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
create-ml-job¶
With the operation create-ml-job you can execute the create jobs API. The create-ml-job operation supports the following parameters:
job-id(mandatory): The name of the machine learning job to create.body(mandatory): Request body containing the definition of the job. Please see the create job API documentation for more details.
This operation works only if machine-learning is properly installed and enabled. This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
open-ml-job¶
With the operation open-ml-job you can execute the open jobs API. The open-ml-job operation supports the following parameters:
job-id(mandatory): The name of the machine learning job to open.
This operation works only if machine-learning is properly installed and enabled. This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
close-ml-job¶
With the operation close-ml-job you can execute the close jobs API. The ``close-ml-job` operation supports the following parameters:
job-id(mandatory): The name of the machine learning job to start.force(optional, defaults tofalse): Whether to forcefully stop an already opened job.timeout(optional, defaults to empty): Amount of time to wait until a job stops.
This operation works only if machine-learning is properly installed and enabled. This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
raw-request¶
With the operation raw-request you can execute arbitrary HTTP requests against Elasticsearch. This is a low-level operation that should only be used if no high-level operation is available. Note that it is always possible to write a custom runner. The raw-request operation supports the following parameters:
method(optional, defaults toGET): The HTTP request method to usepath(mandatory): Path for the API call (excluding host and port). The path must begin with a/. Example:/myindex/_flush.header(optional): A structure containing any request headers as key-value pairs.body(optional): The document body.request-params(optional): A structure containing HTTP request parameters.ignore(optional): An array of HTTP response status codes to ignore (i.e. consider as successful).
sleep¶
With the operation sleep you can sleep for a certain duration to ensure no requests are executed by the corresponding clients. The sleep operation supports the following parameter:
duration(mandatory): A non-negative number that defines the sleep duration in seconds.
Note
The sleep operation is only useful in very limited circumstances. To throttle throughput, specify a target-throughput on the corresponding task instead.
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
delete-snapshot-repository¶
With the operation delete-snapshot-repository you can delete an existing snapshot repository. The delete-snapshot-repository operation supports the following parameter:
repository(mandatory): The name of the snapshot repository to delete.
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
create-snapshot-repository¶
With the operation create-snapshot-repository you can create a new snapshot repository. The create-snapshot-repository operation supports the following parameters:
repository(mandatory): The name of the snapshot repository to create.body(mandatory): The body of the create snapshot repository request.request-params(optional): A structure containing HTTP request parameters.
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
restore-snapshot¶
With the operation restore-snapshot you can restore a snapshot from an already created snapshot repository. The restore-snapshot operation supports the following parameters:
repository(mandatory): The name of the snapshot repository to use. This snapshot repository must exist prior to callingrestore-snapshot.snapshot(mandatory): The name of the snapshot to restore.body(optional): The body of the snapshot restore request.wait-for-completion(optional, defaults toFalse): Whether this call should return immediately or block until the snapshot is restored.request-params(optional): A structure containing HTTP request parameters.
Note
In order to ensure that the track execution only continues after a snapshot has been restored, set wait-for-completion to true and increase the request timeout. In the example below we set it to 7200 seconds (or 2 hours):
"request-params": {
"request_timeout": 7200
}
However, this might not work if a proxy is in between the client and Elasticsearch and the proxy has a shorter request timeout configured than the client. In this case, keep the default value for wait-for-completion and instead add a wait-for-recovery runner in the next step. This has the additional advantage that you’ll get a progress report while the snapshot is being restored.
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
wait-for-recovery¶
With the operation wait-for-recovery you can wait until an ongoing shard recovery finishes. The wait-for-recovery operation supports the following parameters:
completion-recheck-attempts(optional, defaults to 3): It might be possible that the index recovery API reports that there are no active shard recoveries when a new one might be scheduled shortly afterwards. Therefore, this operation will check several times whether there are still no active recoveries. In between those attempts, it will wait for a time period specified bycompletion-recheck-wait-period.completion-recheck-wait-period(optional, defaults to 2 seconds): Time in seconds to wait in between consecutive attempts.
Warning
By default this operation will run unthrottled (like any other) but you should limit the number of calls by specifying one of the target-throughput or target-interval properties on the corresponding task:
{
"operation": {
"operation-type": "wait-for-recovery",
"completion-recheck-attempts": 2,
"completion-recheck-wait-period": 5
},
"target-interval": 10
}
In this example, Rally will check the progress of shard recovery every ten seconds (as specified by target-throughput). When the index recovery API reports that there are no active recoveries, it will still check this twice (completion-recheck-attempts), waiting for five seconds in between those calls (completion-recheck-wait-period).
This is an administrative operation. Metrics are not reported by default. Reporting can be forced by setting include-in-reporting to true.
schedule¶
The schedule element contains a list of tasks that are executed by Rally, i.e. it describes the workload. Each task consists of the following properties:
name(optional): This property defines an explicit name for the given task. By default the operation’s name is implicitly used as the task name but if the same operation is run multiple times, a unique task name must be specified using this property.operation(mandatory): This property refers either to the name of an operation that has been defined in theoperationssection or directly defines an operation inline.clients(optional, defaults to 1): The number of clients that should execute a task concurrently.warmup-iterations(optional, defaults to 0): Number of iterations that each client should execute to warmup the benchmark candidate. Warmup iterations will not show up in the measurement results.iterations(optional, defaults to 1): Number of measurement iterations that each client executes. The command line report will automatically adjust the percentile numbers based on this number (i.e. if you just run 5 iterations you will not get a 99.9th percentile because we need at least 1000 iterations to determine this value precisely).warmup-time-period(optional, defaults to 0): A time period in seconds that Rally considers for warmup of the benchmark candidate. All response data captured during warmup will not show up in the measurement results.time-period(optional): A time period in seconds that Rally considers for measurement. Note that for bulk indexing you should usually not define this time period. Rally will just bulk index all documents and consider every sample after the warmup time period as measurement sample.schedule(optional, defaults todeterministic): Defines the schedule for this task, i.e. it defines at which point in time during the benchmark an operation should be executed. For example, if you specify adeterministicschedule and a target-interval of 5 (seconds), Rally will attempt to execute the corresponding operation at second 0, 5, 10, 15 … . Out of the box, Rally supportsdeterministicandpoissonbut you can define your own custom schedules.target-throughput(optional): Defines the benchmark mode. If it is not defined, Rally assumes this is a throughput benchmark and will run the task as fast as it can. This is mostly needed for batch-style operations where it is more important to achieve the best throughput instead of an acceptable latency. If it is defined, it specifies the number of requests per second over all clients. E.g. if you specifytarget-throughput: 1000with 8 clients, it means that each client will issue 125 (= 1000 / 8) requests per second. In total, all clients will issue 1000 requests each second. If Rally reports less than the specified throughput then Elasticsearch simply cannot reach it.target-interval(optional): This is just1 / target-throughput(in seconds) and may be more convenient for cases where the throughput is less than one operation per second. Define eithertarget-throughputortarget-intervalbut not both (otherwise Rally will raise an error).
Defining operations¶
In the following snippet we define two operations force-merge and a match-all query separately in an operations block:
{
"operations": [
{
"name": "force-merge",
"operation-type": "force-merge"
},
{
"name": "match-all-query",
"operation-type": "search",
"body": {
"query": {
"match_all": {}
}
}
}
],
"schedule": [
{
"operation": "force-merge",
"clients": 1
},
{
"operation": "match-all-query",
"clients": 4,
"warmup-iterations": 1000,
"iterations": 1000,
"target-throughput": 100
}
]
}
If we do not want to reuse these operations, we can also define them inline. Note that the operations section is gone:
{
"schedule": [
{
"operation": {
"name": "force-merge",
"operation-type": "force-merge"
},
"clients": 1
},
{
"operation": {
"name": "match-all-query",
"operation-type": "search",
"body": {
"query": {
"match_all": {}
}
}
},
"clients": 4,
"warmup-iterations": 1000,
"iterations": 1000,
"target-throughput": 100
}
]
}
Contrary to the query, the force-merge operation does not take any parameters, so Rally allows us to just specify the operation-type for this operation. It’s name will be the same as the operation’s type:
{
"schedule": [
{
"operation": "force-merge",
"clients": 1
},
{
"operation": {
"name": "match-all-query",
"operation-type": "search",
"body": {
"query": {
"match_all": {}
}
}
},
"clients": 4,
"warmup-iterations": 1000,
"iterations": 1000,
"target-throughput": 100
}
]
}
Choosing a schedule¶
Rally allows you to choose between the following schedules to simulate traffic:
The diagram below shows how different schedules in Rally behave during the first ten seconds of a benchmark. Each schedule is configured for a (mean) target throughput of one operation per second.
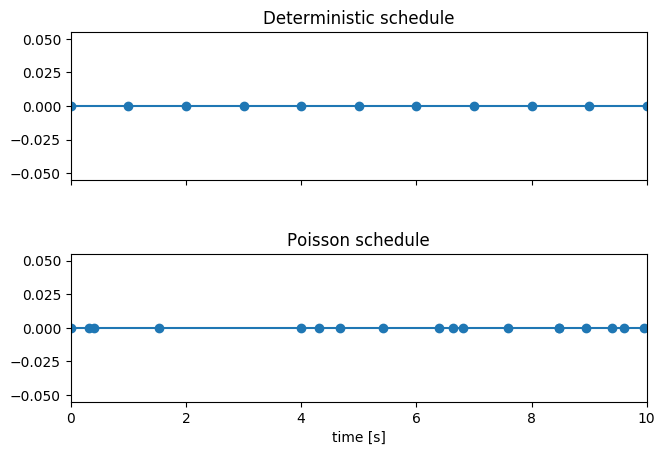
If you want as much reproducibility as possible you can choose the deterministic schedule. A Poisson distribution models random independent arrivals of clients which on average match the expected arrival rate which makes it suitable for modelling the behaviour of multiple clients that decide independently when to issue a request. For this reason, Poisson processes play an important role in queueing theory.
If you have more complex needs on how to model traffic, you can also implement a custom schedule.
Time-based vs. iteration-based¶
You should usually use time periods for batch style operations and iterations for the rest. However, you can also choose to run a query for a certain time period.
All tasks in the schedule list are executed sequentially in the order in which they have been defined. However, it is also possible to execute multiple tasks concurrently, by wrapping them in a parallel element. The parallel element defines of the following properties:
clients(optional): The number of clients that should execute the provided tasks. If you specify this property, Rally will only use as many clients as you have defined on theparallelelement (see examples)!warmup-time-period(optional, defaults to 0): Allows to define a default value for all tasks of theparallelelement.time-period(optional, no default value if not specified): Allows to define a default value for all tasks of theparallelelement.warmup-iterations(optional, defaults to 0): Allows to define a default value for all tasks of theparallelelement.iterations(optional, defaults to 1): Allows to define a default value for all tasks of theparallelelement.completed-by(optional): Allows to define the name of one task in thetaskslist. As soon as this task has completed, the wholeparalleltask structure is considered completed. If this property is not explicitly defined, theparalleltask structure is considered completed as soon as all its subtasks have completed. A task is completed if and only if all associated clients have completed execution.tasks(mandatory): Defines a list of tasks that should be executed concurrently. Each task in the list can define the following properties that have been defined above:clients,warmup-time-period,time-period,warmup-iterationsanditerations.
Note
parallel elements cannot be nested.
Warning
Specify the number of clients on each task separately. If you specify this number on the parallel element instead, Rally will only use that many clients in total and you will only want to use this behavior in very rare cases (see examples)!
challenge¶
If your track defines only one benchmarking scenario specify the schedule on top-level. Use the challenge element if you want to specify additional properties like a name or a description. You can think of a challenge as a benchmarking scenario. If you have multiple challenges, you can define an array of challenges.
This section contains one or more challenges which describe the benchmark scenarios for this data set. A challenge can reference all operations that are defined in the operations section.
Each challenge consists of the following properties:
name(mandatory): A descriptive name of the challenge. Should not contain spaces in order to simplify handling on the command line for users.description(optional): A human readable description of the challenge.default(optional): If true, Rally selects this challenge by default if the user did not specify a challenge on the command line. If your track only defines one challenge, it is implicitly selected as default, otherwise you need to define"default": trueon exactly one challenge.schedule(mandatory): Defines the workload. It is described in more detail above.
Note
You should strive to minimize the number of challenges. If you just want to run a subset of the tasks in a challenge, use task filtering.
Examples¶
A track with a single task¶
To get started with custom tracks, you can benchmark a single task, e.g. a match_all query:
{
"schedule": [
{
"operation": {
"operation-type": "search",
"index": "_all",
"body": {
"query": {
"match_all": {}
}
}
},
"warmup-iterations": 100,
"iterations": 100,
"target-throughput": 10
}
]
}
This track assumes that you have an existing cluster with pre-populated data. It will run the provided match_all query at 10 operations per second with one client and use 100 iterations as warmup and the next 100 iterations to measure.
For the examples below, note that we do not show the operation definition but you should be able to infer from the operation name what it is doing.
Running unthrottled¶
In this example Rally will run a bulk index operation unthrottled for one hour:
"schedule": [
{
"operation": "bulk",
"warmup-time-period": 120,
"time-period": 3600,
"clients": 8
}
]
Running tasks in parallel¶
Note
You cannot nest parallel tasks.
If we want to run tasks in parallel, we can use the parallel element. In the simplest case, you let Rally decide the number of clients needed to run the parallel tasks (note how we can define default values on the parallel element):
{
"parallel": {
"warmup-iterations": 50,
"iterations": 100,
"tasks": [
{
"operation": "default",
"target-throughput": 50
},
{
"operation": "term",
"target-throughput": 200
},
{
"operation": "phrase",
"target-throughput": 200
}
]
}
}
]
}
Rally will determine that three clients are needed to run each task in a dedicated client. You can also see that each task can have different settings.
However, you can also explicitly define the number of clients:
"schedule": [
{
"parallel": {
"warmup-iterations": 50,
"iterations": 100,
"tasks": [
{
"operation": "match-all",
"clients": 4,
"target-throughput": 50
},
{
"operation": "term",
"clients": 2,
"target-throughput": 200
},
{
"operation": "phrase",
"clients": 2,
"target-throughput": 200
}
]
}
}
]
This schedule will run a match all query, a term query and a phrase query concurrently. It will run with eight clients in total (four for the match all query and two each for the term and phrase query).
In this scenario, we run indexing and a few queries in parallel with a total of 14 clients:
"schedule": [
{
"parallel": {
"tasks": [
{
"operation": "bulk",
"warmup-time-period": 120,
"time-period": 3600,
"clients": 8,
"target-throughput": 50
},
{
"operation": "default",
"clients": 2,
"warmup-iterations": 50,
"iterations": 100,
"target-throughput": 50
},
{
"operation": "term",
"clients": 2,
"warmup-iterations": 50,
"iterations": 100,
"target-throughput": 200
},
{
"operation": "phrase",
"clients": 2,
"warmup-iterations": 50,
"iterations": 100,
"target-throughput": 200
}
]
}
}
]
We can use completed-by to stop querying as soon as bulk-indexing has completed:
"schedule": [
{
"parallel": {
"completed-by": "bulk",
"tasks": [
{
"operation": "bulk",
"warmup-time-period": 120,
"time-period": 3600,
"clients": 8,
"target-throughput": 50
},
{
"operation": "default",
"clients": 2,
"warmup-time-period": 480,
"time-period": 7200,
"target-throughput": 50
}
]
}
}
]
We can also mix sequential tasks with the parallel element. In this scenario we are indexing with 8 clients and continue querying with 6 clients after indexing has finished:
"schedule": [
{
"operation": "bulk",
"warmup-time-period": 120,
"time-period": 3600,
"clients": 8,
"target-throughput": 50
},
{
"parallel": {
"warmup-iterations": 50,
"iterations": 100,
"tasks": [
{
"operation": "default",
"clients": 2,
"target-throughput": 50
},
{
"operation": "term",
"clients": 2,
"target-throughput": 200
},
{
"operation": "phrase",
"clients": 2,
"target-throughput": 200
}
]
}
}
]
Be aware of the following case where we explicitly define that we want to run only with two clients in total:
"schedule": [
{
"parallel": {
"warmup-iterations": 50,
"iterations": 100,
"clients": 2,
"tasks": [
{
"operation": "match-all",
"target-throughput": 50
},
{
"operation": "term",
"target-throughput": 200
},
{
"operation": "phrase",
"target-throughput": 200
}
]
}
}
]
Rally will not run all three tasks in parallel because you specified that you want only two clients in total. Hence, Rally will first run “match-all” and “term” concurrently (with one client each). After they have finished, Rally will run “phrase” with one client. You could also specify more clients than there are tasks but these will then just idle.
You can also specify a number of clients on sub tasks explicitly (by default, one client is assumed per subtask). This allows to define a weight for each client operation. Note that you need to define the number of clients also on the parallel parent element, otherwise Rally would determine the number of total needed clients again on its own:
{
"parallel": {
"clients": 3,
"warmup-iterations": 50,
"iterations": 100,
"tasks": [
{
"operation": "default",
"target-throughput": 50
},
{
"operation": "term",
"target-throughput": 200
},
{
"operation": "phrase",
"target-throughput": 200,
"clients": 2
}
]
}
}
This will ensure that the phrase query will be executed by two clients. All other ones are executed by one client.